Fill form to unlock content
Error - something went wrong!
Contact Us
Thank You! We will be in touch.
Saint Louis University Improves Researcher Productivity by Automating Processing of Large Datasets
By Shruthi Sreenivasa Murthy, Lead Solutions Architect, Research Computing Group – Saint Louis University
Sinquefield Center for Applied Economic Research (SCAER) at Saint Louis University (SLU) is at the cutting edge of research, studying human behavior and its economic impact.
I lead the cloud modernization projects across multiple departments and facilities at Saint Louis University. Recently, we enabled researchers to provision compute resources on-demand, control their costs, and automate data conversion.
In this post, I write about how we collaborate with MontyCloud Inc. to run an environment that is fully automated and self-managed. MontyCloud is an AWS Cloud Management Tools Competency Partner.
With MontyCloud DAY2, a no-code autonomous CloudOps platform available on AWS Marketplace, customers can gain multi-account visibility, enable self-service provisioning, detect and fix over 300 compliance and security issues, and automate server and cloud application management—all in just a few clicks.
The Backstory
Saint Louis University is a 200+ year old Jesuit institution with campuses in St. Louis, Missouri, and Madrid, Spain. SLU’s research portfolio is quite diverse. The Sinquefield Center for Applied Economic Research is one of the leading research centers at SLU.
SCAER is a pioneer in studying congregation patterns of people especially during the Covid-19 pandemic. For example, SCAER’s research helps authorities plan the number of vaccinations per day, scheduling patients, traffic control, and people movement at vaccination sites.
The center gets daily dumps of sensitive deidentified geo-data from various sources in petabytes. We don’t get the data in workable formats for the researchers to analyze.
The first step is to convert the data into a workable format and keep it analysis-ready; doing this at a large scale has many challenges. We must also make this data available to a group of users and some external collaborators without compromising on security. The goal is to be able to analyze the data as well as archive the previously analyzed files.
Transforming and managing the data manually was taking the researchers more than a week for one day’s data received from Veraset, a leading global location data provider. This meant SCAER had to commit a few dedicated resources just for data transformation.
Additionally, to handle these large-size datasets we had to deploy compute-heavy Amazon Elastic Compute Cloud (Amazon EC2) instances such as multiple R5 12X large instances. Optimizing the costs and resources deployed on the cloud became a huge challenge.
“SCAER prides itself on being at the leading edge of advance rigorous research on economic growth and social welfare,” says Michael Podgursky, Director of SCAER. “The Research Computing Group at SLU, in collaboration with AWS and MontyCloud, have been successful in enabling our researchers to focus on research as opposed to spending time on unproductive work such as provisioning and data transformation.
“MontyCloud’s DAY2 has helped improve our productivity to a great extent. We further estimate that we’ll save 45% in costs this year, thanks to all the automations,” adds Michael.
Automation Improves Researcher Productivity and Saves Costs
Our first goal was to free SCAER researchers from performing the manual task of data transformation. Automation helps us save valuable researcher time, reduce errors, and make the data available for research faster. We engaged with MontyCloud to help automate the data transformation process.
Veraset uploads the data as Parquet files into a secure Amazon Simple Storage Service (Amazon S3) bucket every day. MontyCloud’s DAY2 platform automatically detects the upload and triggers an AWS Lambda function to start AWS Data Pipeline, which transforms the Parquet files into CSV files.
MontyCloud DAY2 also automatically renames and reorders the data by geolocation, and finally the data is deduplicated and compressed. The transformed data is stored in another secure Amazon S3 bucket. The researchers are notified through a Slack channel when the data is ready, and their analysis algorithms are pointed to the S3 bucket.
This process has simplified what used to take the researchers a week per one day’s data, to a hands-off data availability within 24 hours. The rate of errors is also now reduced to zero.
The whole process is self-administered and self-maintained. We did not have to hire any additional specialized talent. The automation of the number of steps mentioned above has improved our researchers’ productivity by 8x, according to our internal analysis.
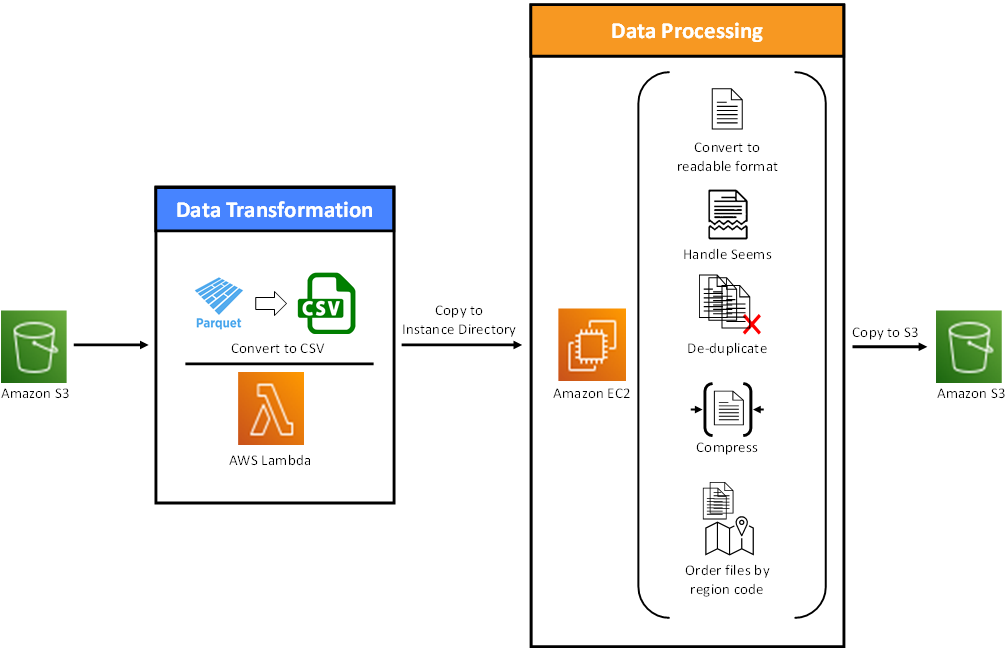
Figure 1 – Automated data transformation workflow.
The next step is to ensure researchers deploy compliant data processing environments. We use multiple Amazon EC2 r5.12xLarge and r5d.xlarge instances.
We wanted to enable the researchers to provision these environments on-demand, in the right virtual private clouds (VPCs), with auto scaling and auto shutdowns to save costs. We now use MontyCloud DAY2 EC2 Blueprint, which is a well-architected provisioning template that pre-configures all of the policies including auto scaling, VPCs, AWS Identity and Access Management (IAM) roles, and automatic shutdown schedules.
MontyCloud DAY2 EC2 Blueprint is available to the researchers through a self-service portal; all they have to do is just click and go. With the DAY2 EC2 Blueprint they no longer have to worry about the infrastructure, as they are provided with the right configuration, security, and protocols conforming to SLU standards.
DAY2 helps us prevent inadvertent errors that can lead to cost over runs and create downstream issues.
Additionally, as the Parquet files are uploaded every day, we are currently consuming more than 500TB of Amazon S3 and growing at 3-5 TB a month. To save costs, we have put S3 lifecycle policies in place to move the data to S3 Standard-IA for 30 days, and to S3 Glacier Deep Archive after 30 days.
Finally, MontyCloud was also able to help us automate mounting and unmounting Amazon Elastic Block Store (Amazon EBS) volumes on demand when EC2 instances are provisioned.
Conclusion
AWS and MontyCloud DAY2 have been helping Saint Louis University’s Research Computing Group in our mission to provide cutting-edge services, optimize computing costs, and performance, which eventually helps the overall research.
Sinquefield Center for Applied Economic Research (SCAER) researchers are now self-sufficient, and the data transformation has improved the productivity. Along with automated provisioning and automated data lifecycle policies, we anticipate we’ll save more than $40,000 this year, while our AWS consumption continues to grow.
Our goal at the Research Computing Group is to help researchers by providing the right infrastructure and computing capabilities that help them to advance their research. One of our ambitious plans is to move some of the high-end applications and high-performance computing workloads from on-premises to AWS.
The content and opinions in this blog are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
.
.
MontyCloud – AWS Partner Spotlight
MontyCloud is an AWS Cloud Management Tools Competency Partner whose no-code autonomous CloudOps platform reduces cloud costs and instantly upskills teams.
Contact MontyCloud | Partner Overview | AWS Marketplace
*Already worked with MontyCloud? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.