Fill form to unlock content
Error - something went wrong!
Contact Us
Thank You! We will be in touch.
Cognizant AWS DataHyperloop: A Continuous Data Journey Towards Developmental Agility and Faster Data Delivery
By Jayaprakash Thakur, Chief DataOps Architect – Cognizant
By James Fallon, Sr. DataOps Architect – Cognizant
By Deepak Singh and Amit Mukherjee, Partner Solutions Architects – AWS
By Aman Azad, Sr. Partner Development Manager – AWS
 |
| Cognizant |
 |
We are facing complex, confusing, and costly challenges in today’s data analytics ecosystem.
Organizations have to deal with myriad components and applications, complicated data pipelines, manual intervention required as multiple process steps, lack of skilled resources, and minimal data automation. It’s generally very tough to extract business value from this complex data maze.
Customers are grappling with the problem of simplifying this ecosystem so the right data can be delivered fast, continuously, and with agility and assurance. There is a dire need for more efficient ways to automate and manage the end-to-end delivery of data to consumers.
The concept of DataOps was born with the goal of solving issues prevalent in old, complex, and monolithic architectures, and to optimize data pipeline architectures with a focus on smart operation and automation.
The resulting methodology yields machine-driven, fast, agile, and autonomous deployment. It also fosters closer collaboration among different teams involved in the process.
Cognizant, an AWS Premier Tier Consulting Partner and Managed Cloud Service Provider (MSP), independently polled its clients and found 91% have already implemented, or are actively looking to integrate, automated DataOps CI/CD pipelines into their existing environments.
To meet this demand for the next generation of automated data pipeline solutions, Cognizant and Amazon Web Services (AWS) jointly built the DataHyperloop solution. It provides a real-time view of DataOps and demonstrates automation of continuous integration, delivery, testing, and monitoring of data assets moving across the data lifecycle on AWS.
Key Benefits
The Cognizant AWS DataHyperloop solution enables data engineers and architects to deploy their main release pipelines. It eliminates configuration time and any manual element to pipeline deployment, which allows developers to focus their efforts entirely on developing code.
The efficiency of the solution results in a 35-40% increase in productivity for data engineers when the pipeline is fully configured.
The dynamic feature branching strategy yields reliable and fully-tested release cycles, and makes post production release bugs virtually extinct. It also delivers data democratization and self-service analytics capabilities for business stakeholders.
Benefits include:
- Up to 35-40% productivity improvement.
- Up to 50-60% lower cost in ~ Year 3.
- Up to 90% data automation.
- Same-day release cycles.
Cognizant AWS DataHyperloop leverages multiple AWS services which are packaged as infrastructure as a code (IaC) to form the core foundation of the solution.
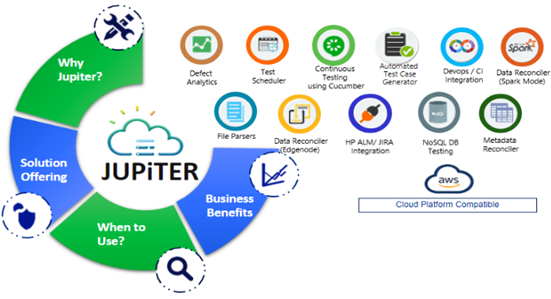
Figure 1 – Cognizant Intelligent Data Works (IDW).
An important and differentiating feature of the solution is its integration with Cognizant’s Data Validation Studio (Jupiter), an end-to-end data validation and certification tool that is part of the greater Cognizant Intelligent Data Works (IDW) solution toolset.
This tool provides metadata-level validation, as well as a data reconciler that performs query-level validation across various data sources. In Cognizant AWS DataHyperloop, the tool validates data across each data layer, ranging from the Amazon Simple Storage Service (Amazon S3) bronze landing bucket with the raw data, all the way to the Amazon Redshift data warehouse.
IDW offers capabilities for automated test case generation, automated test execution, automated scheduling of test suits, and hands-free report generation for overall test runs. Cognizant has been able to achieve up to 90% regression test automation for clients using this tool.
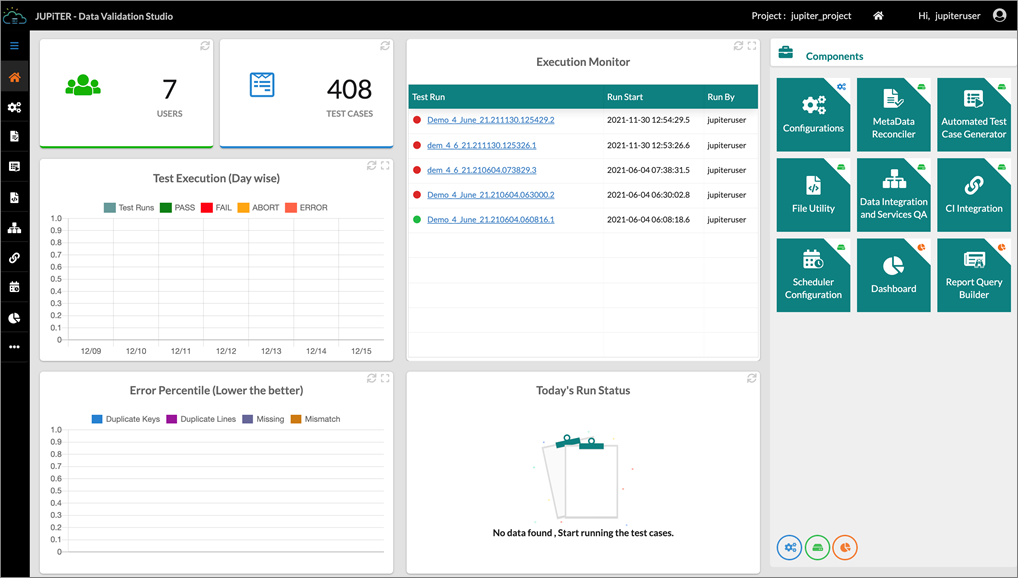
Figure 2 – Sample report of the Cognizant Intelligent Data Works (IDW) tool.
In addition, Cognizant has built a custom AWS X-Ray framework that allows integration with Apache Airflow DAG executions and enables substantial capabilities in the realm of job run analytics and synthetic monitoring.
The entire DAG run is traceable through each AWS service utilized in the data pipeline. It enables detection of problematic task nodes over time and monitors latency.
Cognizant AWS DataHyperloop covers all key aspects of automated data pipelines, including executed trigger-based data processing jobs, monitoring, and alerting of progress of data pipeline execution and observability.
In this post, we explain how Cognizant AWS DataHyperloop delivers automated orchestration of data pipelines through acquisition, integration, transformation, and consumption-ready data delivery, along with seamless operational monitoring and logging.
Solution Approach and Architecture
The Cognizant AWS DataHyperloop solution automates and orchestrates a number of manual processes, such as static code analysis and review, data application build, data pipeline execution, data testing (using Cognizant’s Data Validation Studio), data security scanning, and data application deployment on target environments.
Each stage of this solution can be customized for process additions/deletions as per customer requirements. When developers push changes to their code repository, Cognizant AWS DataHyperloop automatically kicks in to execute the updated artifacts in order to prepare the data application for deployment on targeted environments.
Continuous monitoring and alerts are activated to monitor the overall pipeline and detect job failures, errors, compliance, security, and operational issues, and then notify stakeholders appropriately.
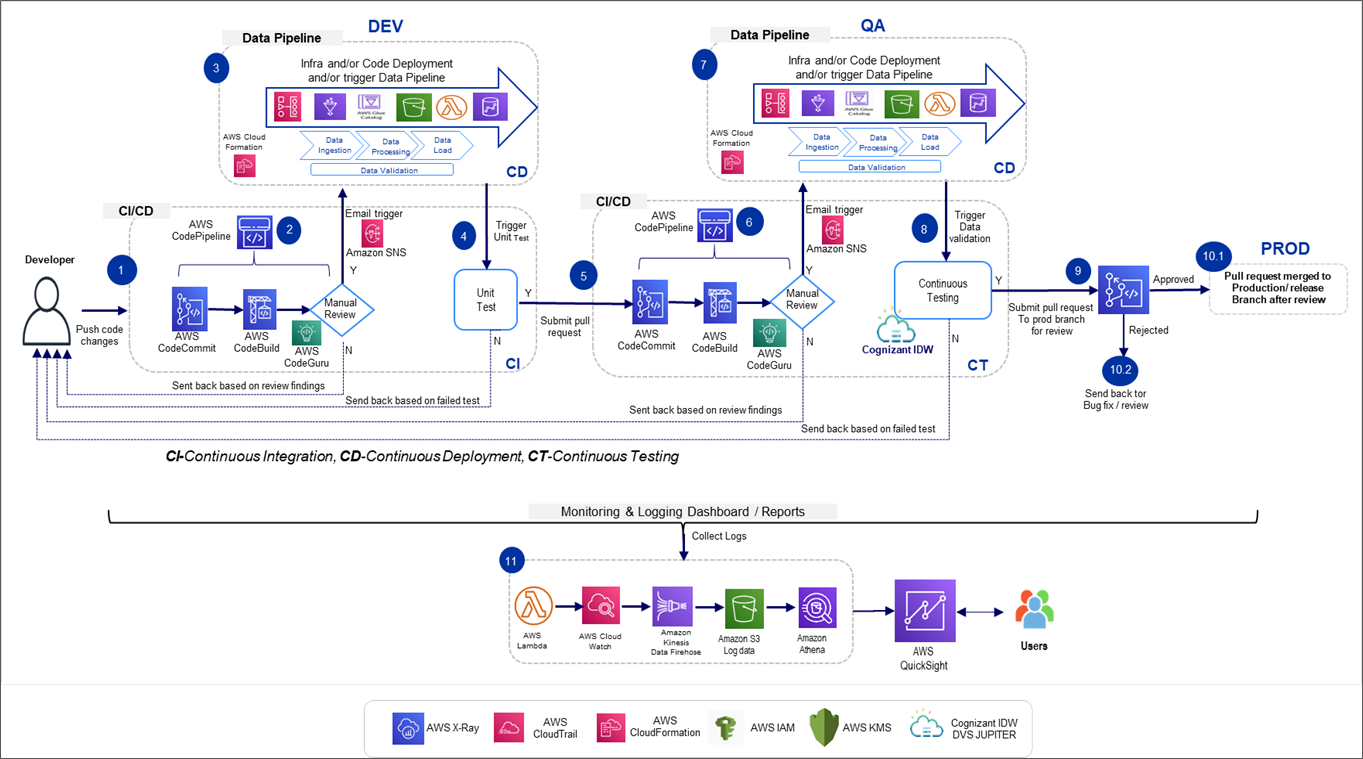
Figure 3 – Cognizant AWS DataHyperloop reference architecture.
Solution Configurations Stages
Configuring the solution consists of five steps:
- Continuous integration—create feature branch and infrastructure updates.
- Code coverage, code analysis, and email notification for approval.
- Continuous data pipeline execution and validation.
- Data application deployment.
- Continuous monitoring and alerts.
Step 1: Continuous Integration
A feature branch is created through AWS CodeCommit as a centralized repository using a Git-based integrated development environment (IDE).
When infrastructure updates or code changes are deployed to this feature branch, it triggers data pipeline for testing. The developer can create as many feature branches as their AWS account resource limits may permit.
The feature branch data pipeline is triggered upon completion of the deployment. This trigger is initiated by a test case ingestion as part of unit test and allows the developer to validate their updates.
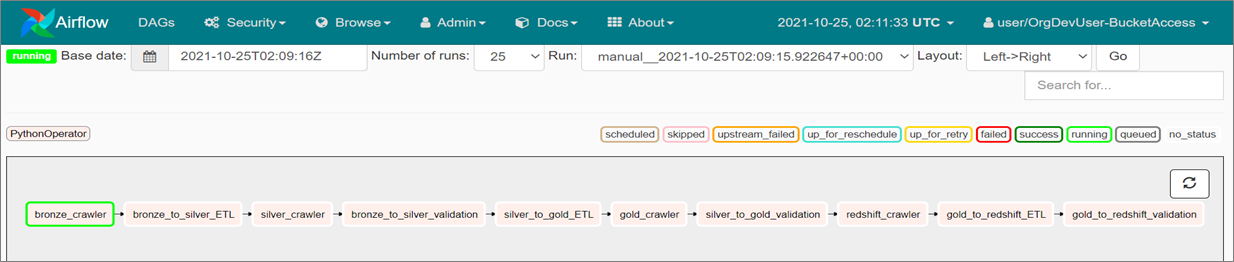
Figure 4 – Sample data pipeline in the Airflow service of the AWS console.
Step 2: Code Coverage, Code Analysis, and Gate-Based Approval
Data application code is checked for code coverage, code scanning, and errors via Amazon CodeGuru. The developer is able to go back and review suggestions to make updates to further improve the code quality.
An email approval notification is sent to a senior developer role for review and approval prior to deploying the code in the release pipeline of the environment.
Step 3: Continuous Data Pipeline Execution and Validation
Layer-based data validation testing is performed to identify data movement and check any inconsistencies. This validation is performed by Cognizant’s Data Validation Studio (Jupiter), an in-house data validation tool that does end-to-end validation of transformations and metadata.
The data validation is done across the data lake/data warehouse in Amazon S3 bronze, Amazon S3 silver, Amazon S3 gold, and Amazon Redshift.
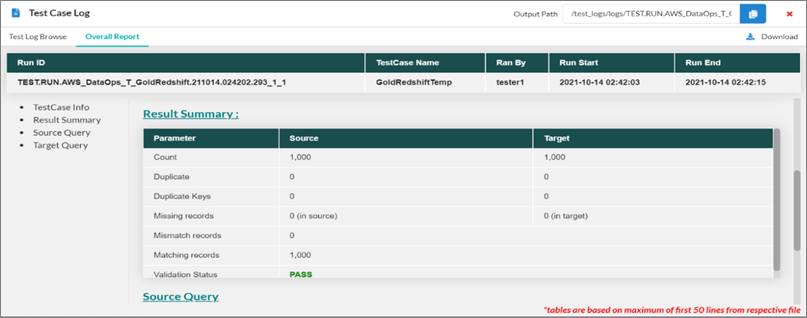
Figure 5 – Sample of Cognizant IDW Jupiter Data Validation UI.
Step 4: Data Application Deployment
After successful completion of all prior stages, the changes go through multiple layers of testing and validation to ensure reliability prior to deployment in the production environment.
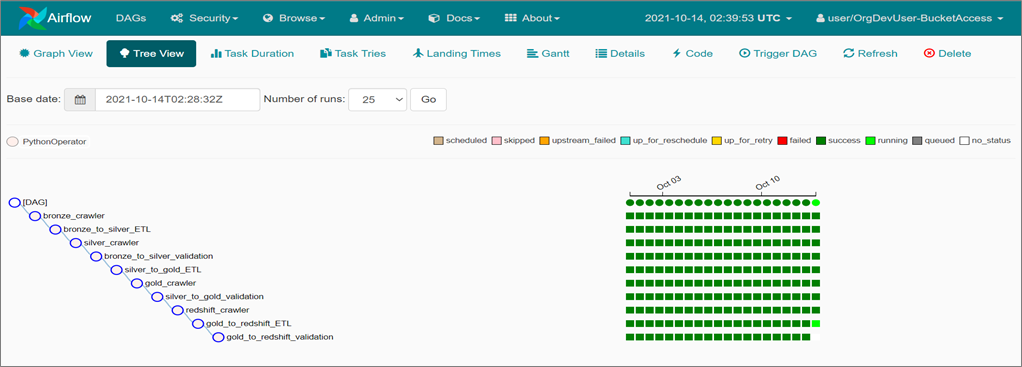
Figure 6 – Sample of Amazon Managed Workflows for Apache Airflow UI data pipeline DAG.
Step 5: Continuous Monitoring and Alerting
Since data pipelines provide the ability to work on multiple streams of real-time data and process enormous data capacities, they must come with the ability to monitor different components to ensure data integrity and continuity.
An alerting mechanism is also required to ensure data quality, which is crucial for reliable business insights.
In this step, Cognizant AWS Data Hyperloop provides the capability for overall pipeline monitoring to detect job failures, errors, compliance, security, operational issues, and notify accordingly.
The solution monitors the infrastructure and pipeline performance, and provides full governance for your platform. It utilizes a custom AWS X-Ray framework for data pipeline analysis and Amazon QuickSight dashboard for deployment monitoring.
AWS X-Ray helps data engineers and stakeholders analyze and debug distributed applications if they run into any issues.
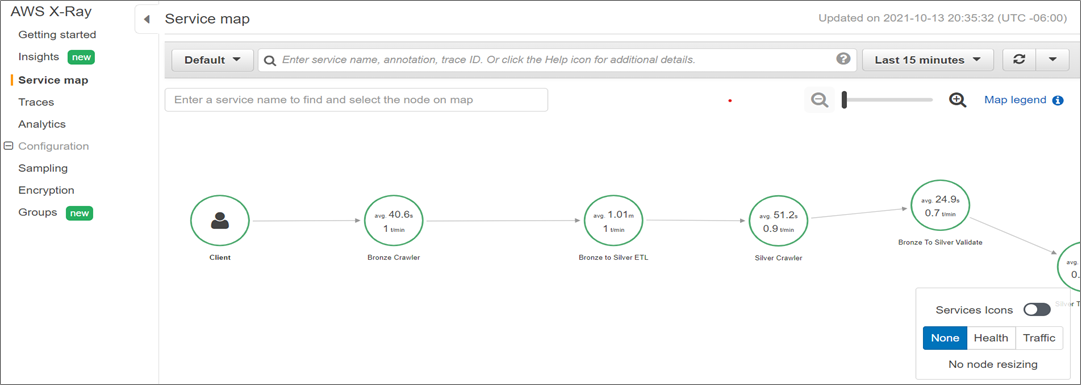
Figure 7 – Sample of the custom AWS X-Ray framework for the data pipeline.
Below is a sample dashboard of deployment monitoring developed using Amazon QuickSight.
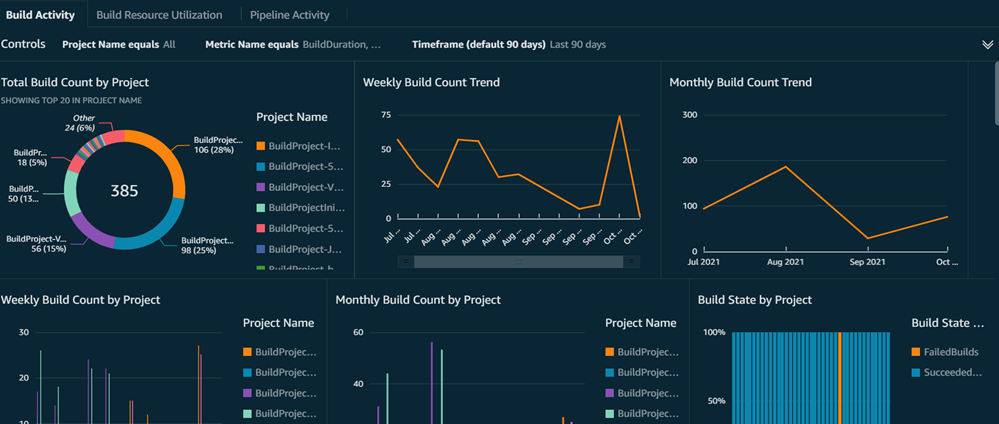
Figure 8 – Sample of Amazon QuickSight CI/CD pipeline monitoring dashboard.
Case Study: DataOps Proposed Implementation
A leading U.S. financial services provider depicted a desire for an agile transformation and integration of DataOps concepts into their AWS Cloud platform. They were intent on an aggressive target to migrate to agile to gain market share with the best project management office (PMO) relationships, service reporting, and multi-vendor distributed development between global teams in mind.
Cognizant proposed a structured “wave approach” to enable teams towards higher agile maturity adoption and designed a fully integrated agile-friendly infrastructure. Automation was idealized as a focal point of the migration, and Cognizant put comprehensive focus on test case automation with individual goals set at the application level.
Cognizant deployed an agile mainframe equipped with extract, transform, load (ETL) shops such as test data, test case management, batch process management.
The solution was rolled out across all lines of business (LOBs) in the organization and achieved a reduced time to market from six months to two months. Over 90% of products met expectations on first release, 85% projects were delivered on a SAFe model, 100% consistency of frameworks and tools usage, over 80% automation across LOBs, and about 15% headcount reduction due to redundancy and inability to transform.
Conclusion
Cognizant AWS DataHyperloop is an end-to-end solution for automating build and deploy processes. It delivers automated orchestration of data pipelines through acquisition, integration, transformation, and consumption-ready data delivery, along with seamless monitoring and logging.
The joint solution provides continuous integration, testing, and delivery automation for data assets moving on the AWS Cloud to speed up data delivery and overall quality.
For customers using AWS data services, or are planning to setup a DataOps pipeline as part of their data transformation journey, Cognizant AWS DataHyperloop delivers data with agility and assurance in all service categories. This includes data management operation, infrastructure and data platform operation, data integration, and data governance.
.
.
Cognizant – AWS Partner Spotlight
Cognizant is an AWS Premier Tier Consulting Partner and MSP that transforms customers’ business, operating, and technology models for the digital era by helping organizations envision, build, and run more innovative and efficient businesses.
Contact Cognizant | Partner Overview
*Already worked with Cognizant? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.