Enabling Security and Compliance in an AWS-Based Big Data Analytics Platform Using Cattle Server Automation and IaC
By Diego Colombatto, Partner Solution Architect – AWS
By Souvik Khamaru, Executive Security Architect – IBM Cloud Security Centre of Competency
 |
| IBM |
 |
This post describes a solution created by IBM during the migration of a big data and analytics platform for one of the top 10 banks worldwide. The primary drivers were cost efficiency, business agility, and performance.
The bank’s setup was based on premises and they decided to migrate the setup to Amazon Web Services (AWS) as part of its cloud-first initiative.
As part of the migration, one of the challenges IBM faced was to design and architect a right-size solution for a legacy data analytics and intelligence solution. It needed to be able to leverage the most advanced cloud environment, and balance upkeep costs and response times associated with the scale and size of the solution.
The big data application was primarily used for security intelligence, context enrichment, and compliance requirements. It provides insights to key security parameters including authorized users and user behavior (User and Entity Behavior Analytics or UEBA).
The data was gathered from different collectors across the world, stored, and processed by the application. Data was made available for direct consuming by stakeholder reports, Security Information and Event Management (SIEM), and other business intelligence applications.
This post details how IBM, an AWS Premier Consulting Partner with the Migration Competency, leveraged AWS-native solutions to design and architect the right-size solution.
IBM enabled high availability (HA) across multiple AWS Availability Zones (AZs) and addressed system maintenance and Amazon Machine Image (AMI) refresh cycles through the principle of “pet and cattle,” delivering an innovative example of infrastructure as code (IaC).
Pet and cattle are typical DevOps concepts where pets imply the tendering, nurture, and care we apply to manage respective applications, servers, and platforms. Cattle, on the other hand, are not afforded with similar attention; rather, they are configured pretty much identically so there is enough fault tolerance and high availability built into the system.
The “pet to cattle” concept was applied to this solution to transform the legacy high availability disaster recovery (HADR) solution to a more robust and cost-effective cattle-based solution through the use of AWS-native services.
Solution Approach and Benefits
As a first step, IBM verified the bank’s legacy, native built-in HADR solution was not agile and responsive enough when migrated as-is (lift and shift) into the AWS Cloud environment.
Given the availability and operations requirements of the data analytics platform, IBM evaluated that an alternative third-party solution would have increased solution complexity and cost.
IBM then proposed a solution leveraging AWS-native services that were best suited to meet the security, availability, and performance requirements of the data analytics solution. It used services like Amazon CloudWatch, AWS Lambda, Amazon Simple Notification Service (SNS), and Auto Scaling Groups to provide better performance, reduced cost, and HADR in one AWS region.
The solution was delivered as IaC using Terraform by HashiCorp, which allowed for rapid development, delivery assurance (via source control and infrastructure state management), and security assurance with multiple Static Application Security Testing (SAST) tools as part of development process.
The main benefits achieved with this solution are:
- Improved data analytics platform availability significantly reduces Auto Scaling Group node rebuild time.
- Reduced platform running costs by removing previous legacy active-active architecture.
- Simplified administration of the big data platform by removing administrative-heavy HADR sync failover solution and using AWS automation to maintain instance health.
- Allows the platform to run on AWS rather than on premises to support the bank’s cloud-first strategy and present cost savings by using cloud-native services rather than inefficient application HA approach.
- Manages bespoke large pet Amazon Elastic Compute Cloud (Amazon EC2) databases as cattle with the use of AWS automation and HA singleton implementation.
Solution Architecture
As mentioned, IBM’s first step was to test the current solution migrated as-is to AWS. It relied on legacy HADR sync utility, and the sync was done by a big data intelligence platform replication service.
This service posed configuration and operations challenges and lacked integration capabilities with AWS-native services, thus limiting appropriate orchestration capabilities.
This is the summary list of solution challenges faced by IBM at this point in the project:
- Solution behavior during failover was not assured.
- Solution required two equal size nodes running and double Amazon Elastic Block Store (Amazon EBS) storage to support synchronization and failover, which unnecessarily increased costs.
- Fail-back process was manual and required node rebuild, and to set original primary as secondary before manual failover could start. This procedure could not be automated.
- Solution is only highly available and is not capable of disaster recovery (DR) spanning across multiple regions.
To solve these challenges and meet the customer’s requirements, IBM proposed a solution to replace the existing HADR sync with a multi-AZ high availability solution. It used automation and existing infrastructure capabilities to attain HA and the required recovery point objective (RPO) and recovery time objective (RTO) for DR within a single region.
The solution also relied on Auto Scaling Groups and Amazon Route 53 to achieve HA and route incoming traffic to data analytics solution, respectively.
Key technical design elements included:
- Highly available and fault tolerant AWS-based data analytics solutions.
- AWS Direct Connect Gateway routable and non-routable subnets in a virtual private cloud (VPC), across all regions to cater for EC2 instances and shared functions, including AWS Lambda, Amazon CloudWatch, AWS Systems Manager logs, Auto Scaling Groups, and Amazon Simple Storage Service (Amazon S3) gateways.
- Multi-AZ auto scaling for singleton EC2 instance node with associated automation to support cattle principle. This was handled via Auto Scaling Group lifecycle hooks to allow for periodic AMI refresh cycles and HA health actions.
- Persistent Amazon EBS data are maintained by automation hooks. They are used to perform EBS snapshots which are restored to EBS in the same AZ that auto scaling chooses to place the EC2 instance.
- Fixed Elastic Network Interface (ENI) per AZ to allow for Amazon Route 53 traffic routing based on the EC2 health-check Lambda that tracks EC2 across Availability Zone.
Cattle EC2 automated management process (as shown in Figure 1) ensures high availability of the infrastructure and supports the business application during changes, such as when a new application must be released or a patch needs to be applied to update functionalities.
For this management process, Amazon EC2 automation is used and the AMI refresh cycle is integrated with auto scaling features. This enables automated deployments of new instances in Auto Scaling Groups.
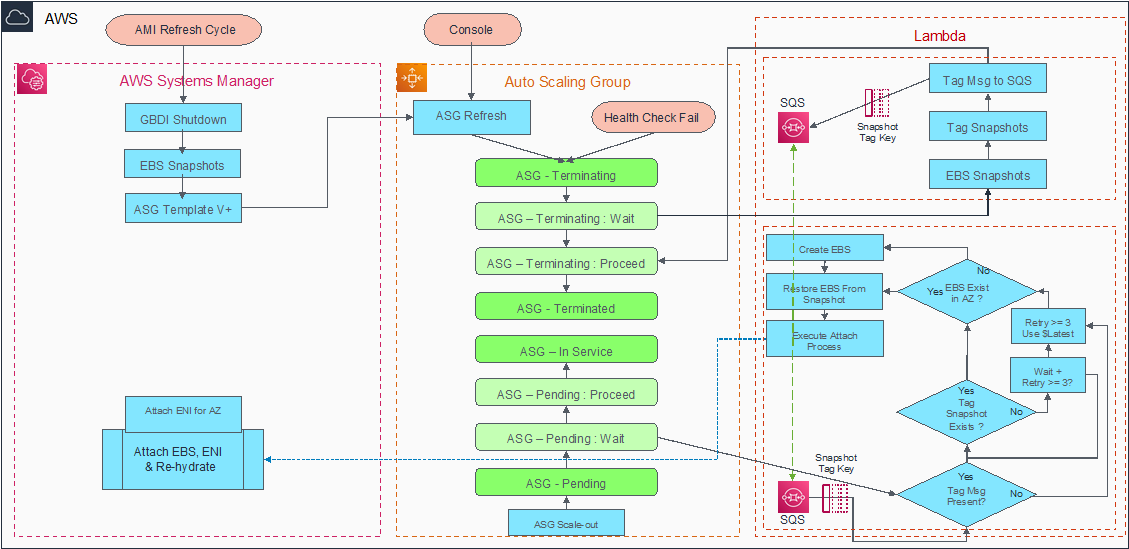
Figure 1 – High-level steps of Cattle EC2 automated management process.
Network Design with Security Elements
These are the key elements of the network design:
- Minimize use and exposure of routable IP addresses to lower security risk of routing or traversal to the internal network.
- Limit subnet traversal risk by having subnets for specific functionality.
- Reduce risk of routable IP exhaustion by having IP-hungry services in their own subnet.
- Internal routable subnet hosted the EC2 instance where communications to the Direct Connect Transit Gateway were controlled by security groups.
- The non-routable subnets hosted Lambda functions for Auto Scaling Group lifecycle hooks and Amazon Route 53, virtual private cloud (VPC) endpoints, and VPC endpoint gateway for Amazon S3.
- Security groups have been designed to use granular service-to-service binding, using explicit controls on all traffic destinations.
- Amazon S3 gateway routes were configured to be distinctly separate and only exposed to the EC2 via granular AWS Identity and Access Management (IAM) policies on both VPC endpoints and EC2 service role.
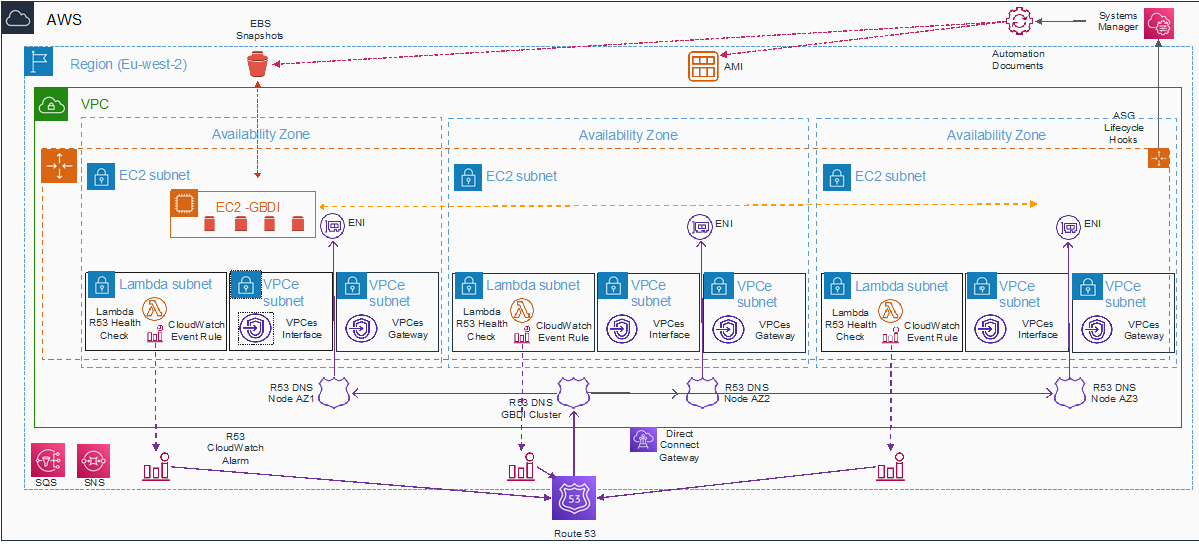
Figure 2 – Network design with security elements.
AMI Refresh Leveraging Auto Scaling Group Workflow
The challenge with respect to managing a large bespoke data analytics solution in the cloud is not limited to hosting, routing, and high availability. A significant roadblock remains on how to manage the AMI refresh cycle and vulnerability management in a secure and non-disruptive manner, without data loss or gateway node cache exhaustion.
To accommodate this process, the database application was installed across four Amazon EBS volumes, which must persist the AMI refresh cycle which replaces the root EBS volume.
IBM leveraged Auto Scaling Group lifecycle hook automation to ensure EBS snapshots are taken on termination. These are uniquely tagged, and the tag key is added to Amazon Simple Queue Service (SQS) for use in EC2 creation by Auto Scaling Group automation.
To achieve cloud-native high availability, the Auto Scaling Group spanned all three AZs within the region in a singleton self-healing pattern. Whichever AZ the Auto Scaling Group decides to create the new EC2 instance in, lifecycle automation uses the key placed in SQS during termination to retrieve the correct snapshot and restore EBS in the current AZ without data loss.
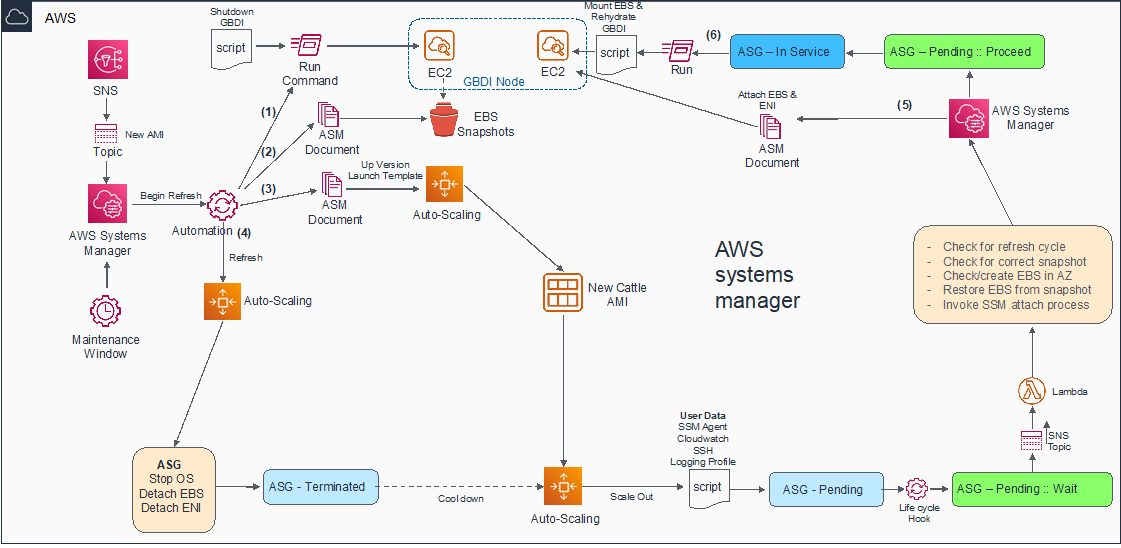
Figure 3 – AMI refresh workflow.
High Availability Design
These are the key high availability aspects of the solution:
- Solution utilized auto scaling in a multi-AZ, self-healing singleton design where auto scaling tracks the health status of the node. Upon failure of the health check, whether it’s an instance failure or AZ-level failure, the solution rebuilds an instance in an alternate AZ, if required.
- Using Auto Scaling Group lifecycle hooks, this solution tries to restore Amazon EBS snapshot in the original AZ and use a Lambda function if EBS must be created in another AZ. In the latter case, Lambda reads from SQS the unique EBS snapshot tag that’s required to restore the EBS.
- Amazon EBS volumes will be created just in time for use to minimize cost.
- Auto Scaling Group lifecycle hook automation is natively multi-Availability Zone.
- Amazon Route 53 DNS tracks ‘healthy’ nodes using health checks and provides failover traffic routing.
- Leveraged Auto Scaling Group lifecycle hooks for consistent node rebuild automation, regardless of which AZ the node is built in.
- Amazon EC2 instance is provisioned using an AWS Systems Manager document automation during rebuild cycle.
Conclusion
In this post, we discussed the primary challenges involved in achieving high availability, disaster recovery, and security compliance of a large bespoke data analytics solution when migrating to AWS.
Specifically, we discussed how pet instances can be treated as cattle as required for modern cloud architectures, and how to devise a secure end-to-end solution allowing required communications through VPC bindings.
IBM security services were able to address all challenges by integrating various components within AWS so the customer’s desired business outcome and operational efficiency were achieved.
IBM has a dedicated team of specialists available to help customers understand how to apply this solution to their needs, and how on-premises pet instances and similar legacy solution can be migrated to secure, scalable, and highly available architectures, with significant cost savings on AWS.
.
.
IBM – AWS Partner Spotlight
IBM is an AWS Premier Consulting Partner and MSP that offers comprehensive service capabilities addressing both business and technology challenges that clients face today.
Contact IBM | Partner Overview
*Already worked with IBM? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.