How to Use Amazon SageMaker to Improve Machine Learning Models for Data Analysis
By Rupesh Kothapalli, AWS Architect/DevOps Engineer at BizCloud Experts
By Nagesh Kunamneni, Chief Technical Officer at BizCloud Experts
 |
Enterprises don’t require just any data to help them improve their business decisions—they require the right kind of data.
You need to ask the right questions in the right way to get the answers you’re looking for, and in a form you can use. Though it sounds simple, developing those questions for massive amounts of data can be a daunting task.
To deal with this challenge, data scientists typically employ MapReduce tools like Hadoop to store the data, Pig or Hive to retrieve it, Python or Java to write Spark, and Hive applications to analyze it. However, because that data is stored in different formats, methods, devices, and locations, it takes a lot of work to develop the algorithms that produce desired outputs.
Machine learning (ML) can be extremely useful in this regard because it helps data scientists build those algorithms. In theory, data scientists state the type of data they are trying to produce, and through repeated processing cycles, they “train” the ML algorithm to produce exactly that type of data.
In practice, though, machine learning development is a complex, expensive, and iterative process that’s further complicated by the absence of tools that integrate the entire workflow. As a result, data scientists must stitch together disparate tools and workflows, which can insert errors into the data and algorithms.
Amazon SageMaker solves this by providing all of the components used for machine learning in a single toolset. This allows models to get to production faster with much less effort and at lower cost. Amazon SageMaker includes preconfigured Python libraries for training ML algorithms and deploying custom data analysis models.
BizCloud Experts is an AWS Partner Network (APN) Advanced Consulting Partner with multiple AWS Service Delivery designations. We helped Neiman Marcus use machine learning models to build personalized recommendations for their shoppers based on previous browsing and shopping patterns.
In this post, we’ll walk you through the data modeling process we used, the tools we employed, and the results we achieved for Neiman Marcus.
Our Data Modeling Process
BizCloud Experts have been an integral part of an AWS Cloud Center of Excellence (CCOE) team at Neiman Marcus. In that capacity we helped their internal product teams perform architecture reviews, develop best practices, comply with governance, and build frameworks the rest of the organization can leverage to transform their business using AWS.
We employed Amazon SageMaker to help us develop and train ML algorithms for recommendation, personalization, and forecasting models that produce the kind of data Neiman Marcus was looking for.
Our starting point was a typical data modeling process, which includes these general steps:
- Build, develop, and test models; for example, recommendations and predictive models.
- Clean and transform data.
- Gather summary statistics and perform exploratory data analysis (EDA) on the transformed data.
- Tune and enhance data models that help achieve business objectives.
When we altered our data modeling process to include the capabilities of Amazon SageMaker, it evolved into this:
- Build the data lake.
- Configure Amazon SageMaker.
- Schedule workloads.
Let’s look at each step in more detail.
Step 1: Building the Data Lake
We needed to create a data lake that could scale and give the data scientists at Neiman Marcus an easy way to collect, store, and query the information they already had.
When we began, the customer’s data was distributed across multiple on-premises servers from SAS, Hadoop, and GPU, making it difficult to query and analyze the data from a single platform. Furthermore, because on-premises storage was limited, any data analysis operations that would result in additional data were not feasible.
Creating the data lake shown in Figure 1, we used a Snowflake data warehouse to extract, transform, and load (ETL) data between databases; custom Hive tables to store frequently accessed data; and Amazon Simple Storage Service (Amazon S3) to create a unified storage endpoint for Neiman Marcus data scientists to access all of that data.
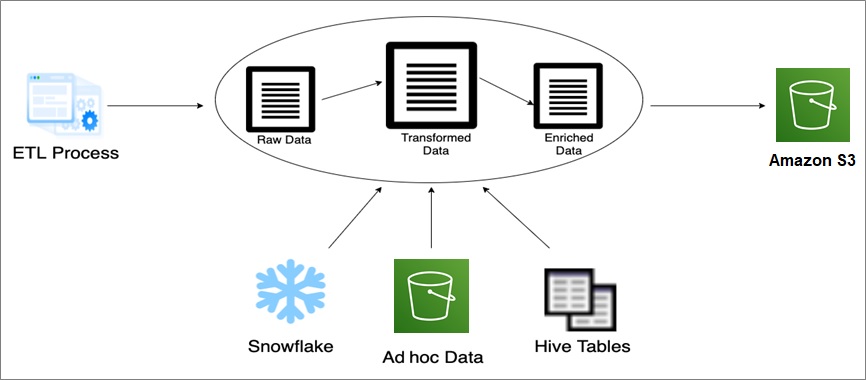
Figure 1 – Components in our data lake.
The lifecycle management in Amazon S3 allowed us to store the customer’s existing data, plus the additional data we generated, without fear of overwriting or deleting it. By storing data in the cheapest way relative to its frequency of use, S3’s storage tiers saved money.
Step 2: Configuring Amazon SageMaker
One of the benefits of using AWS compute and storage resources compared to on-premises resources is that we can scale up or down as needed, and we can change the ratio of compute to storage depending on the job. This approach reduces both the capital and operational expenses for customers.
To take even better use of AWS elastic resources, we used Amazon EMR. The standard MapReduce framework is designed to run massive amounts of unstructured data in parallel across a distributed cluster of processors or stand-alone computers.
The AWS implementation does the same thing across a Hadoop cluster of virtual servers in Amazon Elastic Compute Cloud (Amazon EC2), storing the data in S3 with only light configuration required. By running our Spark and Hive jobs in parallel on Amazon EC2 clusters, Amazon EMR allowed us to complete our data retrieval jobs in 40 percent less time.
Neiman Marcus is focused on continuously innovating and improving customer experiences, and Amazon SageMaker enabled them to rapidly develop, deploy, update, and scale ML models to enhance and orchestrate customer experiences.
“In a matter of a few clicks, data scientists can now turn on various instances to develop different models in parallel, and then ensemble those models to invoke a service to meet business needs, allowing reduced time to market,” says Sohel Khan, Director, Data Science at Neiman Marcus. “BizCloud Experts helped with our migration efforts and got us up to speed in no time with using AWS services, thereby improving the efficiency of our development teams.”
For its part, Amazon SageMaker gave the data scientists at Neiman Marcus direct access to the Amazon EMR clusters so they could submit their Hive and Spark data retrieval jobs.
To restrict public access, all of the AWS compute and storage resources assigned to our customer were placed on the same private subnet inside an Amazon Virtual Private Cloud (VPC).
The data scientists saved their code in Jupyter notebooks in Amazon SageMaker, where they are secure, can be shared, edited, and managed.
Figure 2 – Configuration of Amazon SageMaker with Amazon EMR-backed Spark.
Step 3: Scheduling Workloads
The following diagram shows the flow of data between the data lake, data scientists, and our machine learning models.
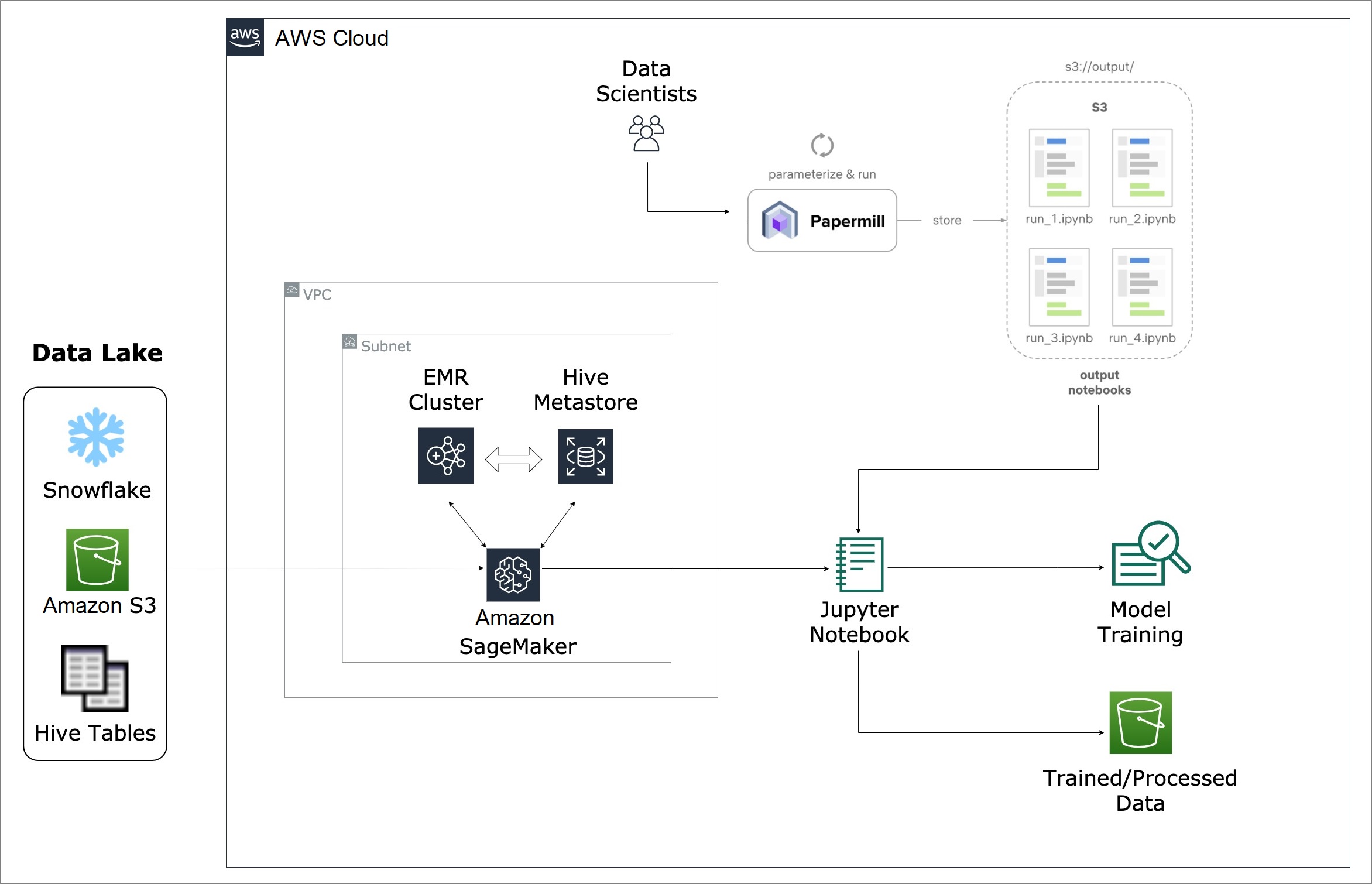
Figure 3 – Data analytics and model training using Amazon EMR and Amazon SageMaker.
As discussed earlier in this post, we kept the jobs written by the Neiman Marcus data scientists in Amazon SageMaker Jupyter notebooks. We kept job data, including ML models and other notebook outputs such as custom data and Hive tables, in Amazon S3 where it could be consumed by other Neiman Marcus teams.
“The BizCloud team brought in their expertise of Agile, DevOps, and serverless solutions along with their architecture and advisory services,” says Hemanth Jayaraman, Director, DevOps & Cloud Center of Excellence at Neiman Marcus. “This allowed the team to rapidly optimize data lake costs and leverage it as the foundation for a data scientist decisioning platform.”
BizCloud also used Amazon S3 to store the logs of our jobs, including detailed reports of notebook execution, with debugging at the individual cell. To avoid duplication, job-specific logs were overwritten daily.
We used Papermill to structure and schedule our workloads as cron jobs. Papermill is an open-source tool that lets you run your code on different parameters (data sets) and, depending on the output of the code, decide which job to run next.
Data scientists at Neiman Marcus were performing repetitive tasks such as sorter, aggregator, and self-join transformation jobs on the raw data against variables like different brand categories or date of purchase. We developed the jobs to handle multiple variables and run against the specified ones on a cron schedule.
For examples, see the sample code below:.
0 16 * * 4 AWS_PROFILE=<aws-profile> /usr/local/bin/papermill /home/ec2-user/SageMaker/<file-name>.ipynb s3://<bucket-name>/<file-name>.json -k python3
The data received from multiple stores and different internal teams was pushed to the data lake at the end of the day. This raw data goes through the ETL process defined in the scheduled scripts. The format of the data received is constant, and the ETL’s tasks log the output data for that respective day into custom Apache Hive tables.
The output of the on-premises jobs run by Amazon SageMaker was analyzed by data scientists and used for training ML models. Typical data includes customer buying history, recent sale trends, total number of sales for the day, most bought item from the store, and other metrics that help business intelligence teams provide insights to other teams at Neiman Marcus.
The jobs running on the cloud comprise mostly of ETL and ML recommendation algorithms, as well as model training jobs developed with modern open source libraries. The jobs running on the on-premises environment consisted of the SAS scripts and Hive code developed with older libraries the hardware could handle. There was no load balancing between on-premises and cloud jobs.
Lessons Learned
When trying to optimize our process for the large amount of data we were processing, we ran into problems with the Spark configuration properties and the Spark Executor/Driver memory on the Amazon EMR cluster.
We identified the Spark configuration defaults based on the core and task instance types in the cluster, and changed them to handle the amount of data being submitted to Amazon EMR.
By running a production load of data against the Amazon EMR cluster and monitoring its performance, we also developed cost optimization techniques such as using instance fleet configuration running spot instances for Task nodes on the Amazon EMR cluster.
To address the problem with the Spark Executor/Driver memory, we monitored the performance of the Amazon EMR cluster against the application history and other metrics like applications failed, nodes running, HDFS utilization, and total load the cluster monitoring tab provides.
We then fine-tuned the cluster configuration to utilize instance fleets, which allowed us to specify target capacities for on-demand and spot instances within each fleet. This approach also gave us the flexibility to run workloads on a diversified set of instance types. It allowed us to size the Spark executors using multiple instance types, and its advanced properties helped us set actions in case the spot instance provisioning timed out.
We configured the instance fleets to use 20 percent on-demand and 80 percent spot instances, which helped us keep the running nodes to maximum while optimizing the cost.
Results
By employing this process with Neiman Marcus, we achieved these results:
- The customer had a unified storage endpoint for accessing all of their customer data.
- Hadoop and ETL processing ran 50 percent faster on AWS.
- Developer teams improved efficiency by 30 percent because their development environments on Amazon SageMaker were isolated from each other, allowing them to run experimental jobs without affecting each other’s work.
- Jobs ran in 40 percent less time after we migrated from their on-premises SAS or Hive code to Python scripts that used the latest ML libraries.
- Our customer did not have to concern themselves with maintaining or updating hardware or source code, since it was all handled by Amazon SageMaker. Any new source code or code backup was in place through Git any time the instance was stopped and started outside of regular work hours.
“BizCloud Experts is an integral part of our Cloud Center of Excellence team,” says Srikanth Victory, Vice President, Data & Analytics Technology at Neiman Marcus. “Their knowledge of AWS services accelerated our digital transformation through workload automation, and they helped reduce risk to business and operations by moving our data to a more resilient and secure IT environment.”
Summary
With AWS, Neiman Marcus has been able to perform advanced data analytics and develop data science models to achieve business goals at increased speed and agility.
Developing machine learning models is a complex, expensive process that can waste time and energy on repetitive tasks. By combining the right set of AWS tools in the right way, you can improve the efficiency of your data scientists and ML developers. That’s what BizCloud Experts did for Neiman Marcus.
We used AWS storage services to create a unified data lak,e and Amazon EMR to perform advanced data analytics on huge amounts of data. We configured Amazon SageMaker to run notebook instances backed by Spark and submit workloads to Amazon EMR.
Finally, we used Papermill to run, execute, and parameterize Jupyter notebooks on a cron schedule.
The content and opinions in this blog are those of the third party author and AWS is not responsible for the content or accuracy of this post.
.
.
BizCloud Experts – APN Partner Spotlight
BizCloud Experts is an APN Advanced Technology Partner. They help customers accelerate digital transformation projects through consulting, development, collaboration, and integrations.
Contact BizCloud Experts | Practice Overview
*Already worked with BizCloud Experts? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.